模型文件那几十个G里,到底装了些什么?
📌 来源: 本文基于微信公众号文章整理改编
🔗 原文链接: https://mp.weixin.qq.com/s/eDg6jTrapS5PobtORdxHCQ
📝 版权归原作者所有,本文仅用于学习分享
概述
如果你曾经在 Hugging Face 或其他模型仓库下载过一个 7B 参数的大语言模型,你会发现一个令很多人困惑的现象:这个模型标称只有 70 亿个参数,但下载的文件大小却高达约 14GB。更让人不解的是,打开这个文件后,里面既不是人类可读的代码,也不是文字,而是一堆巨大的数字数组。
这一篇是"AI 底层原理"系列的第二篇。我们将逐层拆解模型文件的内部结构,用通俗的方式讲清楚以下几个核心问题:
- 权重(Weights)到底是什么? 它们如何承载了模型的"智能"?
- 量化是怎么压缩文件的? 14GB 怎么能压到 3.5GB?
- 不同格式有什么区别? safetensors、GGUF、GPTQ 各自适合什么场景?
- 模型文件里到底装了些什么? 从嵌入层到输出层,每一层的作用是什么?
上一篇我们揭示了上下文窗口的真相——128K 窗口不等于真的能用满,超出约 32K 后模型的"记忆"能力显著下降。那么模型本身呢?它的文件里到底存了什么?今天我们就来一探究竟。
一、模型文件不是代码,是数字
很多人第一次接触大语言模型时,以为从网上下载的模型文件里是某种程序代码——就像下载一个 Python 脚本或 Java 程序那样,打开就能看到逻辑和算法。
其实完全不是这样。模型文件里全是数字。 准确地说,是一堆浮点数(Floating Point Numbers)。
1.1 权重的本质
这些数字有一个专业名字:权重(Weights)。
权重不是程序员手写上去的,而是在模型训练过程中通过海量计算反复调整得到的。要理解权重是什么,我们先来简单回顾一下模型的训练过程。
训练刚开始时,模型内部的所有权重都是随机生成的小数——就像一块空白的画布。然后,训练数据(通常是数万亿个文本片段)被源源不断地输入模型。每一次输入,模型都会做出预测,然后和正确答案进行比较。根据预测误差,模型会通过反向传播算法对所有权重进行微小的调整。
经过数万亿次这样的迭代后,每个权重都被微调到了一个特定的值。这个值决定了:当输入出现某种特定的模式时,对应的神经元应该放大信号还是缩小信号。
1.2 模型不知道"知识"
这里有一个非常重要的理解:模型文件不包含任何"知识"的文字形式。
模型不知道"北京是中国首都"这句话。它甚至不知道"北京"这两个字是什么意思。它只有一堆数字——这些数字恰好让它在看到"中国的首都是"这个输入时,输出"北京"的概率最高。
这个概念很多人一开始很难接受。我们习惯于认为知识是文字、是事实、是可以在字典里查到的内容。但大语言模型的"知识"完全是另一种形态——它是一种数值模式,一种通过高维向量空间中的数值关系来编码信息的方式。
这就像人脑中的突触连接强度——大脑不是用文字存储知识的,而是用神经元之间物理连接的强弱来编码信息。模型文件的权重,就是人工神经网络中"连接强度"的数字化表达。
1.3 训练过程的数据流
初始状态:70亿个随机小数
↓
输入训练数据(数万亿个token)
↓
前向传播:输入 → 嵌入层 → 32层Transformer → 输出层 → 预测结果
↓
计算损失:预测结果 vs 正确答案
↓
反向传播:根据误差调整所有70亿个权重
↓
重复数万亿次...
↓
最终状态:70亿个精调后的权重 → 模型文件每一次迭代对权重的调整都非常微小(可能只改变小数点后第 8 位),但数万亿次累积下来,这些微小的调整就塑造出了模型的语言能力。
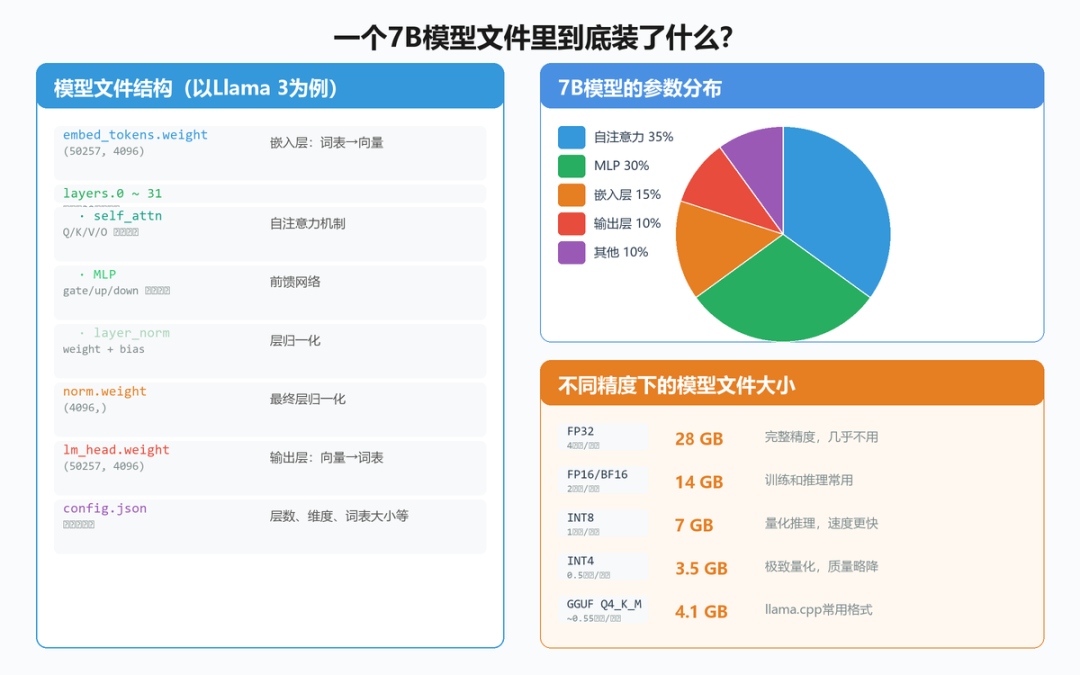
二、模型文件的内部结构
一个典型的开源模型文件(如 safetensors 格式)包含以下几个核心部分。了解这些结构,不仅能帮助你理解模型是怎么工作的,还能在调试和微调时少走很多弯路。
2.1 嵌入层(Embedding Layer)——输入翻译器
- 功能: 把 Token ID 转换成稠密向量
- 参数规模: 约 2 亿参数(以 7B/4096 维度模型为例)
- 权重矩阵形状: (词表大小, 向量维度) = (32000, 4096)
嵌入层是模型的"输入翻译器"。大语言模型处理的第一步,是把输入的文本拆分成 Token(一个 Token 大约相当于 0.7 个英文单词或 1-2 个汉字)。每个 Token 都有一个对应的 ID 数字。嵌入层的任务就是把这些离散的 ID 映射到连续的向量空间中。
在这个向量空间里,语义相近的 Token 会有相近的向量。比如"猫"和"狗"的向量会比"猫"和"电脑"的向量更接近。这就是模型能够理解语义相似性的基础。
2.2 Transformer 层——核心大脑
这是模型最重要的部分。以 Llama 架构为例,7B 模型通常有 32 层 Transformer,占总参数量的约 90%。可以说,Transformer 层就是模型的"大脑"。
每一层 Transformer 包含两大模块:
① 自注意力机制(Self-Attention)
自注意力是 Transformer 架构的灵魂。它让模型在生成每一个词时,都能"看到"前面所有词的上下文。这就是 Transformer 比传统的 RNN/LSTM 强大得多的核心原因——全局注意力 vs 顺序处理。
每一层的自注意力包含四个权重矩阵:
| 矩阵 | 形状 | 功能 |
|---|---|---|
| Q(Query) | 4096 × 4096 | 生成查询向量,表示"我在找什么" |
| K(Key) | 4096 × 4096 | 生成键向量,表示"我提供了什么" |
| V(Value) | 4096 × 4096 | 生成值向量,表示"我的内容是什么" |
| O(Output) | 4096 × 4096 | 合并注意力结果 |
Q、K、V 三个矩阵协同工作,计算出每个位置对其他所有位置的"注意力权重"。O 矩阵则把这些注意力结果转换回标准的向量空间。
② 多层感知机(MLP / Feed-Forward Network)
MLP 是模型的"思考引擎"。在注意力机制提取了上下文信息后,MLP 对这些信息进行进一步处理和转换。
每一层的 MLP 包含三个权重矩阵:
| 矩阵 | 形状 | 功能 |
|---|---|---|
| Gate | 4096 × 11008 | 门控投影(Llama 使用 SwiGLU 激活) |
| Up | 4096 × 11008 | 上投影,扩展到高维空间 |
| Down | 11008 × 4096 | 下投影,压缩回原始维度 |
中间维度 11008 大约是输入维度 4096 的 2.7 倍。这个"先扩展再压缩"的结构是 Transformer 的标准设计——在更高维的空间中进行信息处理,然后再投影回来,这样能捕捉到更复杂的模式。
2.3 层归一化(Layer Normalization)——稳定器
- 功能: 稳定训练过程,防止梯度爆炸或梯度消失
- 参数规模: 很少,每层约 8192 个参数(4096 维度的缩放因子和偏移量)
层归一化确保每一层的输出在一个合理的数值范围内。如果没有归一化,信号在经过 32 层传递后可能会变得极大或极小,导致训练崩溃。
2.4 输出层(LM Head)——输出翻译器
- 功能: 把最后一层的向量转换回 Token 概率分布
- 参数规模: 和嵌入层大小相当,约 1.3 亿参数
- 权重矩阵形状: (词表大小, 向量维度) = (32000, 4096)
输出层和嵌入层在结构上是对称的。它把模型处理后的 4096 维向量映射回 32000 维的词表空间,计算每个候选 Token 的生成概率。最后通过 Softmax 函数得到概率分布,从中采样或选择最可能的 Token 作为下一个输出。

2.5 配置文件:模型的"蓝图"
下载模型时还有一个关键文件:config.json
{
"architectures": ["LlamaForCausalLM"],
"hidden_size": 4096,
"intermediate_size": 11008,
"num_hidden_layers": 32,
"num_attention_heads": 32,
"num_key_value_heads": 8,
"vocab_size": 32000,
"max_position_embeddings": 8192,
"rms_norm_eps": 1e-05
}这个文件是模型的"蓝图",告诉加载器:
- 模型有多少层?→ 32 层
- 每个矩阵的维度多大?→ 4096 维
- 注意力头数多少?→ 32 个 Query 头,8 个 KV 头(GQA 架构)
- 词表大小多少?→ 32000
- 最大上下文长度?→ 8192 Token
没有 config.json,权重文件就是一堆无法解读的数字。 就像拿到了一本用未知编码写的书——每个字符(权重值)都在,但你不知道该按什么规则来解读它们。
2.6 用代码直接查看权重
如果你对某个模型的内部结构好奇,可以用 Python 直接打开查看:
from safetensors import safe_open
with safe_open("model-00001-of-00004.safetensors", framework="pt") as f:
# 查看所有张量名称
print(f.keys())
# 输出示例:
# ['model.embed_tokens.weight', 'model.layers.0.self_attn.q_proj.weight', ...]
# 查看嵌入层权重
embed = f.get_tensor("model.embed_tokens.weight")
print(f"嵌入层形状: {embed.shape}") # torch.Size([32000, 4096])
# 查看第一层注意力 Q 矩阵
q_weight = f.get_tensor("model.layers.0.self_attn.q_proj.weight")
print(f"Q矩阵形状: {q_weight.shape}") # torch.Size([4096, 4096])
print(f"Q矩阵前3x3值:\n{q_weight[:3, :3]}")运行上面的代码,你会看到每一个权重矩阵就是一个巨大的多维数组。单个权重值本身没有明确的语义——比如一个权重值 0.02345678 不代表任何具体的概念——只有它们组合在一起时,才涌现出了语言理解能力。
三、不同精度,文件大小差 4 倍
同一个模型,用不同的数值精度保存,文件大小可以相差 4 倍以上。这是实践中最常遇到的问题之一,也是理解模型部署的关键。
3.1 精度对比表
| 精度格式 | 每参数位数 | 每参数字节数 | 7B模型大小 | 质量损失 | 适用场景 |
|---|---|---|---|---|---|
| FP32 | 32 位 | 4 字节 | ~28 GB | 无(基准) | 模型训练、学术研究 |
| FP16 | 16 位 | 2 字节 | ~14 GB | 极小(<0.5%) | GPU 推理、模型微调 |
| BF16 | 16 位 | 2 字节 | ~14 GB | 极小(<0.5%) | 现代 GPU 训练 |
| INT8 | 8 位 | 1 字节 | ~7 GB | 较小(1-3%) | CPU 推理、边缘设备 |
| INT4 | 4 位 | 0.5 字节 | ~3.5 GB | 中等(5-10%) | 消费级硬件、移动端 |
3.2 深入理解精度
精度取舍的本质问题是:用多少位二进制数来存储每一个参数。
FP32(32 位浮点数): 这是最精确的格式。每个参数用 4 个字节(32 位)来存储。它能表示的数值范围非常大(约 10^-38 到 10^38),精度也很高(约 7 位有效数字)。但代价是 7B 模型需要约 28GB 的显存,大多数消费级显卡根本装不下。只有专业级 GPU(如 A100 80GB)才能运行 FP32 的 7B 模型。
FP16(16 位浮点数): 精度略有下降(约 3 位有效数字),数值范围也缩小了,但空间直接减半。绝大多数 GPU 推理和微调都使用这个格式。现代 NVIDIA 显卡有专门的 FP16 计算单元,推理速度甚至可能比 FP32 更快。
BF16(Brain Float 16): Google 开发的格式。和 FP16 一样是 16 位,但它把更多的位分配给了指数部分(动态范围),更少的位分配给了尾数(精度)。这个设计让它更适合训练过程,因为训练中经常遇到极大或极小的梯度值。需要较新的 GPU(Ampere 架构及以上)支持。
INT8(8 位整数): 把浮点数转换为整数存储。每个参数只用 1 个字节。7B 模型从 14GB 压缩到约 7GB。质量损失通常在 1-3% 以内,大部分日常应用场景感受不到区别。INT8 的优势是计算速度快——整数运算比浮点运算高效得多。
INT4(4 位整数): 极致压缩。每个参数只用 0.5 个字节(两个参数共用一个字节)。7B 模型从 14GB 压缩到约 3.5GB。质量损失约 5-10%,在复杂推理任务上能感受到差异,但日常对话和创意写作几乎不受影响。
3.3 2026年主流推理格式
GGUF 格式(llama.cpp 生态)
GGUF 是 2026 年最通用的模型格式。它由 llama.cpp 项目维护,支持 CPU 和 GPU 推理。
| GGUF 量化级别 | 文件大小(7B) | 质量评级 | 推荐场景 |
|---|---|---|---|
| Q2_K | ~2.7 GB | ★★★ | 极限压缩,快速浏览 |
| Q3_K_M | ~3.3 GB | ★★★★ | 低配设备日常使用 |
| Q4_K_M | ~4.1 GB | ★★★★☆ | 性价比最高,推荐 |
| Q5_K_M | ~4.8 GB | ★★★★★ | 质量优先 |
| Q6_K | ~5.5 GB | ★★★★★ | 接近 FP16 |
| Q8_0 | ~7.2 GB | ★★★★★★ | 几乎无损 |
GPTQ 格式(GPU 推理专用)
GPTQ 是由 AutoGPTQ 项目推广的格式,专为 NVIDIA GPU 优化。Int4 GPTQ 格式的 7B 模型约 3.5GB,在 GPU 上推理速度最快。
AWQ 格式(激活感知量化)
AWQ 的核心理念是:不是所有权重都同等重要。通过分析模型在推理过程中的激活模式,识别出哪些权重对输出影响大,哪些影响小。对重要权重保留更高精度,对不重要的权重大胆压缩。结果就是 INT4 量化的质量接近 FP16。
3.4 如何选择?
- 只有 CPU / Mac 用户 → GGUF 格式(推荐 Q4_K_M)
- 有 NVIDIA GPU + 追求速度 → GPTQ-Int4
- 有 NVIDIA GPU + 追求质量 → AWQ-Int4
- 有 24GB+ 显存 → FP16 原版
- 有 80GB 显存 → 可以跑 FP32
四、量化到底损失了什么?
4.1 量化的直观理解
量化就是把更少的位数存储同一个数字。让我们用一个直观的例子来理解:
原始 FP16 值:0.12345678
INT8 量化后: 0.123 (保留 3 位小数)
INT4 量化后: 0.12 (保留 2 位小数)信息确实丢失了,但丢失的是精度,不是核心内容。
这就像把一张 4K 分辨率的图片压缩成 1080P——边缘的细节少了,但图片的主要内容、颜色、构图都还在。你仍然能清楚地看出图片画的是什么。
4.2 量化对模型能力的影响
不同的使用场景对量化损失的敏感度不同:
| 任务类型 | FP16 | INT8 | INT4 | 说明 |
|---|---|---|---|---|
| 日常对话 | 完美 | 完美 | 几乎完美 | 聊天、问答不受影响 |
| 代码生成 | 完美 | 完美 | 轻微瑕疵 | 复杂代码可能缺少变量名 |
| 数学计算 | 完美 | 轻微误差 | 明显误差 | INT4 可能算错多位数运算 |
| 复杂推理 | 完美 | 几乎完美 | 可感知下降 | 多步逻辑推理受影响 |
| 创意写作 | 完美 | 完美 | 几乎完美 | 创意表达不太受影响 |
| 翻译 | 完美 | 完美 | 轻微瑕疵 | 专业术语可能不够准确 |
4.3 2026年的量化技术
量化技术在 2026 年已经相当成熟,出现了多种先进的量化方案:
混合专家模型(MoE)量化
MoE 架构的模型(如 Mixtral 8x7B)由多个"专家"子网络组成,每次推理只激活其中一部分。量化时可以只对不活跃的专家层进行低精度压缩,保持核心层和活跃专家的高精度。这样在质量和压缩率之间取得更好的平衡。
AWQ(Activation-aware Weight Quantization,激活感知权重量化)
AWQ 的核心思想是观察模型在推理时的激活模式,找出对输出影响最大的那些权重,对这些"重要权重"保留更高精度。这种方法让 INT4 量化模型的质量非常接近 FP16 原版。
SmoothQuant
SmoothQuant 解决了 INT8 推理在 CPU 上的难题。它通过在激活值和权重之间进行数学变换,让两者都更容易量化。使得 INT8 推理在纯 CPU 环境下也能高效运行。
4.4 什么时候不该量化?
以下场景建议使用 FP16 或 BF16 格式,避免量化:
- 模型微调/训练: 量化后的精度损失会导致梯度计算不准确,微调效果大打折扣。
- 数学/逻辑推理为主的任务: 量化损失在精确计算任务上更加明显,INT4 模型可能在多位数运算中出错。
- 有足够显存的场景: 既然显卡装得下 FP16 的完整模型,为什么要牺牲质量?
五、开源模型的完整文件清单
下载一个典型的开源模型(如 Llama 3 8B),你会得到以下文件结构:
5.1 核心文件列表
model-00001-of-00004.safetensors ~4.9 GB 权重分片 1
model-00002-of-00004.safetensors ~4.9 GB 权重分片 2
model-00003-of-00004.safetensors ~4.9 GB 权重分片 3
model-00004-of-00004.safetensors ~3.2 GB 权重分片 4
config.json ~0.5 KB 模型架构配置
tokenizer.model ~1.5 MB Tokenizer 词表文件
tokenizer_config.json ~1 KB Tokenizer 行为配置
special_tokens_map.json ~0.2 KB 特殊 Token 映射总计:约 18GB
5.2 为什么权重要分片?
你可能会好奇:为什么不把所有权重存在一个文件里?
原因是单个文件太大,会带来很多问题:
- 网络传输困难: 一个 18GB 的文件下载失败后需要从头再来。分成 4 片后,某一片失败了只需重传那一片。
- 内存管理: 加载时可以按需加载分片,而不是一次性读取整个文件。
- 存储限制: 某些文件系统对单个文件大小有限制。
- 并行下载: 多个分片可以同时下载,充分利用带宽。
4 个 safetensors 文件在模型加载时会被合并成一个完整的模型。对推理来说,它们就是一个整体。
5.3 Tokenizer 为什么是独立的?
tokenizer.model 是一个完全独立的文件,它包含了模型的 Token 词表——即模型认识的所有"单词"的列表。它和权重文件分开存储有几个重要原因:
- 共享性: 不同模型可能共用同一个 Tokenizer。比如 Llama 2 和 Llama 3 的词表不同,但同一代的不同变体可能共用。
- 独立性: Tokenizer 不需要 GPU 加载,它在 CPU 上就能运行。
- 更新方便: 更新模型权重时不需要重新训练或下载 Tokenizer。
5.4 推理用户的最佳选择
如果你只是想用模型做推理(不打算训练或微调),下载 GGUF 格式是最明智的选择:
- 一个文件搞定, 不用处理分片问题。
- 大小合理, 根据量化精度约 4-7GB。
- 开箱即用, 直接用 llama.cpp 或 Ollama 加载,不需要额外的转换步骤。
# 方法一:用 Ollama 一键运行(最简单)
ollama pull llama3:8b
ollama run llama3:8b
# 方法二:用 llama.cpp 加载 GGUF 文件
./llama-cli -m llama-3-8b-Q4_K_M.gguf \
-p "你好,请介绍一下自己" \
-n 256 --temp 0.7六、常见模型格式对比
6.1 safetensors vs PyTorch .bin
在 safetensors 出现之前,Hugging Face 上的模型主要使用 PyTorch 的 .bin 格式(pickle 序列化)存储权重。
| 特性 | safetensors | PyTorch .bin (pickle) |
|---|---|---|
| 安全性 | ✅ 安全(只包含张量数据,不可执行代码) | ⚠️ 不安全(pickle 可执行任意代码) |
| 加载速度 | ✅ 零拷贝,内存映射,极快 | ❌ 需要完整反序列化,较慢 |
| 兼容性 | ✅ 多框架支持(PyTorch/TensorFlow/JAX) | ⚠️ 仅 PyTorch |
| 推荐度 | ⭐⭐⭐⭐⭐ | ⭐⭐ |
safetensors 是 2026 年的事实标准。 它不仅安全(避免了 pickle 反序列化漏洞),而且加载速度更快,支持内存映射——不用把整个模型读进内存就能访问部分权重。这对于显存受限的场景非常重要。
6.2 GGUF vs GPTQ vs AWQ 横向对比
| 特性 | GGUF | GPTQ | AWQ |
|---|---|---|---|
| 硬件支持 | CPU + GPU(通用性最强) | GPU(仅 CUDA) | GPU(仅 CUDA) |
| 量化方法 | 统一量化(每组 256 个参数一组缩放因子) | 逐通道量化(每个通道独立缩放) | 激活感知量化(按重要性差异化精度) |
| 推理框架 | llama.cpp / Ollama / MLX | AutoGPTQ / ExLlama / vLLM | vLLM / TGI / AutoAWQ |
| INT4 质量 | 较好 | 一般 | 最好 |
| CPU 支持 | ✅ 完美 | ❌ 不支持 | ❌ 不支持 |
| 易用性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
6.3 选择建议速查
- Mac / Apple Silicon → GGUF(用 MLX 或 llama.cpp)
- 只有 CPU → GGUF Q4_K_M 或 Q5_K_M
- NVIDIA GPU + 追求速度 → GPTQ-Int4
- NVIDIA GPU + 追求质量 → AWQ-Int4
- 显存充足(24GB+)→ FP16 原版
- 显存 80GB+ → 可以跑 FP32 完整精度
七、动手实践:用 safetensors 探索模型内部
7.1 查看模型参数统计
from safetensors import safe_open
import json
# 打开模型文件
with safe_open("model-00001-of-00004.safetensors", framework="pt") as f:
# 查看所有张量
keys = list(f.keys())
print(f"该分片包含 {len(keys)} 个张量")
# 统计总参数量
total_params = 0
for key in keys:
tensor = f.get_tensor(key)
params = tensor.numel() # 元素总数
total_params += params
print(f"该分片总参数量: {total_params:,}")7.2 观察权重的数值分布
import torch
with safe_open("model-00001-of-00004.safetensors", framework="pt") as f:
q_weight = f.get_tensor("model.layers.0.self_attn.q_proj.weight")
print(f"形状: {q_weight.shape}")
print(f"数据类型: {q_weight.dtype}")
print(f"最大值: {q_weight.max().item():.6f}")
print(f"最小值: {q_weight.min().item():.6f}")
print(f"均值: {q_weight.mean().item():.6f}")
print(f"标准差: {q_weight.std().item():.6f}")运行后你可能会看到:权重值大多分布在 -1 到 1 之间,均值接近 0,标准差在 0.02 左右。这就是经过训练后的权重分布——它们被精细地调整到了能协作工作的数值。
八、FAQ
Q1:模型越大越好吗?
不一定。7B 模型做日常对话、简单问答已经够用;13B 在逻辑推理和代码生成上表现更好;70B+ 模型适合专业场景和复杂任务。但大模型需要更多硬件资源。关键是根据你的实际需求和硬件条件来选择,而不是盲目追求参数量。
Q2:量化后的模型可以微调吗?
不建议。量化过程丢失了精度(INT4 丢失了约 87.5% 的精度信息),而微调需要精确的梯度计算。在量化模型上微调的效果通常很差。如果需要微调,建议使用 FP16 或 BF16 格式的原始模型,微调完成后再量化。
Q3:不同量化格式之间能互相转换吗?
可以,但有代价。GGUF 格式的量化模型可以先反量化回 FP16,再重新量化为其他格式。但每次转换都会有额外的精度损失。最佳实践是:从原始 FP16 模型直接量化为目标格式,避免中间转换。
Q4:safetensors 和 checkpoint 有什么区别?
- safetensors: 是完整的模型权重文件,只包含张量数据,可以直接用于推理。
- checkpoint: 是训练过程中保存的中间状态,除了模型权重外,还包含优化器状态、学习率、训练步数等信息。checkpoint 文件通常更大,不用于推理场景。
Q5:模型文件能"修复"或"更新"吗?
权重文件本身不能直接编辑修复——你无法打开 safetensors 文件然后手动修改某个权重值来获得更好的效果。但可以通过以下方式改变模型行为:
- 微调(Fine-tuning): 用新数据重新训练模型,调整权重
- 模型合并(Model Merge): 合并多个模型的权重,综合各自的优点
- LoRA(Low-Rank Adaptation): 添加小规模的适配层(通常只有几十 MB),不改动原始权重
Q6:为什么同一个模型有不同版本?
你在 Hugging Face 上经常看到同一个模型有多个版本,比如 Llama-3-8B、Llama-3-8B-Instruct、Llama-3-8B-Chat。它们的区别在于:
- Base 版本: 预训练模型,只经过基础训练,适合做微调
- Instruct 版本: 经过指令微调,能更好地理解指令和对话
- Chat 版本: 经过对话微调,更适合聊天场景
文件结构相同,但权重值不同——因为它们经历了不同的训练阶段。
总结
核心要点回顾
模型文件全是数字,不是代码。 70 亿个浮点数,是训练过程中反复调整得到的结果。文件里没有文字形式的知识,只有数值模式。理解这一点,是理解大语言模型工作方式的第一步。
推理用 GGUF 格式最方便。 一个文件 4-7GB,Ollama 或 llama.cpp 直接加载,不用处理分片问题。对于大多数只想"用起来"的用户来说,GGUF 是最佳选择。
INT4 量化质量损失可接受。 14GB 压缩到 3.5GB,大部分日常场景感受不到区别。复杂推理任务建议使用 INT8 更稳妥,在质量和体积之间取得平衡。
理解模型结构有助于更好地使用它。 知道权重是什么、量化怎么工作、不同格式的优缺点,能帮助你在模型选择、硬件规划和性能优化上做出更明智的决策。
下期预告
AI 知识为什么会过时? 知识截止日期与更新机制:为什么 AI 不知道昨天发生的事?敬请期待。
看完有启发的话,欢迎分享给更多朋友一起学习!
参考资料
- Hugging Face - safetensors 文档: https://huggingface.co/docs/safetensors
- llama.cpp 项目 - GGUF 格式说明: https://github.com/ggerganov/llama.cpp
- GPTQ 量化论文: https://arxiv.org/abs/2210.17323
- AWQ 量化论文: https://arxiv.org/abs/2306.00978
- SmoothQuant 论文: https://arxiv.org/abs/2211.10438
- 原文链接: https://mp.weixin.qq.com/s/eDg6jTrapS5PobtORdxHCQ
⚖️ 版权声明: 本文基于微信公众号文章改编整理,版权归原作者所有。转载请注明来源。