Ollama MacOS 部署:一键安装 + 局域网服务,适配 OpenClaw 无 token 限制 🍏
📌 来源: 程序员老孙 | 转载说明: 本文经整理排版后发布,版权归原作者所有
此前分享 Ollama Windows 部署 和 OpenClaw + Ollama(魔塔源) 后,众多果粉粉丝留言想要 Mac 版教程。就有了这个文章。
⚙️ 前期准备
系统要求
- macOS 12.0 及以上(推荐 macOS 13+,兼容性更佳)
- 支持全架构:Apple Silicon(M1/M2/M3/M4)、Intel x86_64
硬件要求(实测 MacBook Air M4)
- 内存:≥16GB(推荐 32GB,多轮对话/复杂任务更流畅)
- 存储:≥20GB(Qwen3.5 9B 模型约 6.6GB,预留缓存/其他轻量模型空间)
📥 第一步:一键安装 Ollama
Mac 安装 Ollama 提供三种方式:
方案 1:官网 DMG 包安装(新手友好)
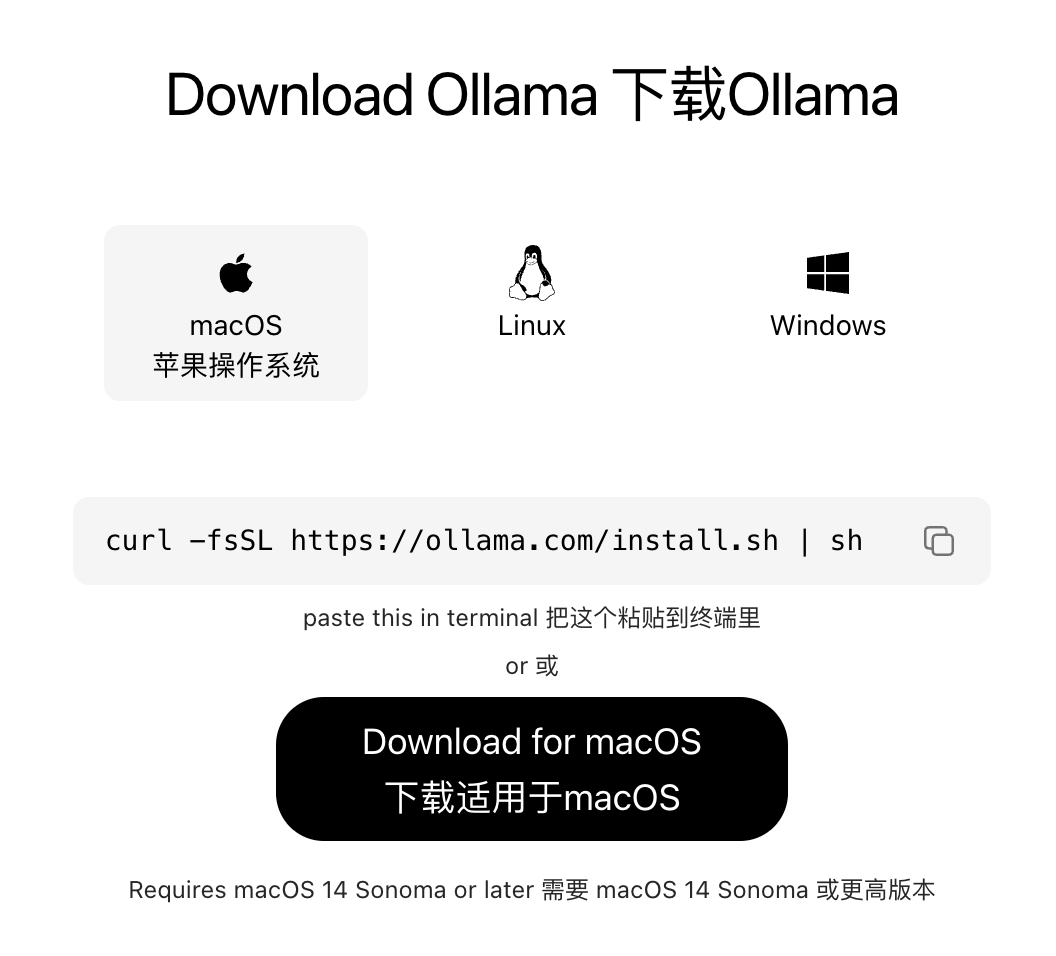
- 访问 Ollama 官网「www.ollama.com」,点击「Download for Mac」
- 下载压缩包,解压后将
Ollama.app拖入「应用程序」文件夹 - 双击打开,首次打开弹出权限提示,点击「允许」
- 菜单栏出现羊驼图标,说明 Ollama 服务已自动启动
方案 2:Homebrew 命令安装(开发者首选)
# 安装 Ollama
brew install ollama
# 启动后台服务(关闭终端仍可运行)
brew services start ollama
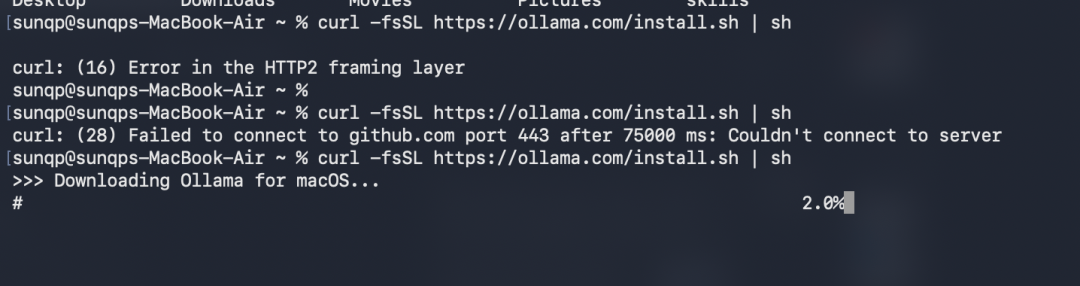
方案 3:官方 curl 脚本安装(全架构通用)
# 安装(可能需要多次尝试,网络问题)
curl -fsSL https://ollama.com/install.sh | sh
# 手动启动服务
ollama serve验证安装
ollama --version
# ✅ 成功示例:ollama version 0.1.8
📦 第二步:加载 Qwen3.5 模型
Qwen3.5 官方发布 0.8B/2B/4B/9B 四款轻量模型,实测筛选出 Mac 全系适配的最优版本。
📊 Qwen3.5 官方模型推荐
| 模型名 | 体积 | 核心优势 | 适配场景 |
|---|---|---|---|
qwen3.5:9b | ~6.6GB | 性能最强、中文优化、多模态支持,兼顾速度与能力 | 日常办公、代码生成、复杂问答、多模态处理(首选) |
qwen3.5:4b | ~3.4GB | 轻量均衡、启动快,内存占用低 | 基础问答、简单文本处理、低内存设备备用 |
qwen3.5:2b | ~2.7GB | 极致轻量、推理速度最快 | 快速问答、轻量化调用 |
qwen3.5:0.8b | ~1.0GB | 超小体积、几乎无内存压力 | 极简对话、嵌入式调用 |
终端执行 9B 模型加载命令(Mac 全系首选)
ollama run qwen3.5:9b首次运行自动下载模型文件,下载完成后终端显示 >>> Send a message,表示模型可本地交互。
Mac 专属性能优化(M4 亲测有效)
# 强制开启Metal GPU加速(M4专属)
launchctl setenv OLLAMA_METAL 1
# KV缓存量化为8-bit,减少内存占用40%
launchctl setenv OLLAMA_KV_CACHE_TYPE q8_0
# 启用Flash Attention,速度提升20%+
launchctl setenv OLLAMA_FLASH_ATTENTION 1
# 只保留1个模型在内存,避免溢出
launchctl setenv OLLAMA_MAX_LOADED_MODELS 1
# 空闲5分钟后卸载模型(平衡内存与加载速度)
launchctl setenv OLLAMA_KEEP_ALIVE 300
# 限制为4个线程(适配M4性能核,避免过热)
launchctl setenv OLLAMA_NUM_THREADS 4💡 本地测试:直接输入问题(如「写一个 Mac 端 Python 文件批量处理脚本」),模型实时返回结果,验证运行正常。

🌐 第三步:配置局域网服务,Mac 变全端 AI 服务器
默认 Ollama 仅本地(127.0.0.1)可访问,配置后支持同一局域网内的手机、平板、其他电脑任意调用。
3.1 核心:设置全局环境变量
# 设置局域网访问(关键步骤)
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
# 验证配置
echo $OLLAMA_HOST
# 显示 0.0.0.0:11434 即配置成功
3.2 重启 Ollama 服务
DMG 包安装版:
- 点击菜单栏羊驼图标,选择「Quit Ollama」
- 重新从「应用程序」打开 Ollama.app
Homebrew 安装版:
brew services restart ollama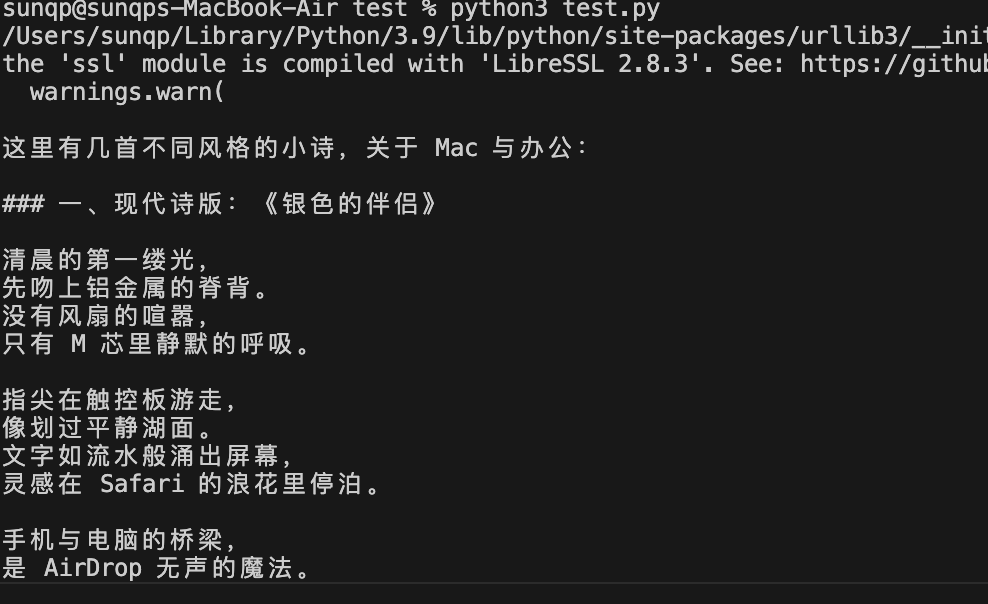
3.3 放行防火墙(如已开启)
- 打开「系统设置」→「网络」→「防火墙」
- 点击锁图标解锁,输入本机密码
- 点击「防火墙选项」,勾选「自动允许已下载的签名软件接收传入连接」
- 若弹出 Ollama 网络访问提示,直接点击「允许」
🧪 第四步:测试局域网服务连通性
本地测试
创建 test_ollama.py 文件:
import requests
import json
# 替换为你的 Mac 局域网 IP(如 192.168.1.100)
url = "http://192.168.1.100:11434/api/generate"
data = {
"model": "qwen3.5:9b", # 对应加载的Qwen3.5 9B模型
"prompt": "写一首关于Mac办公的小诗",
"stream": True
}
response = requests.post(url, json=data, stream=True)
for line in response.iter_lines():
if line:
res = json.loads(line)
if "response" in res:
print(res["response"], end="", flush=True)
if res.get("done"):
break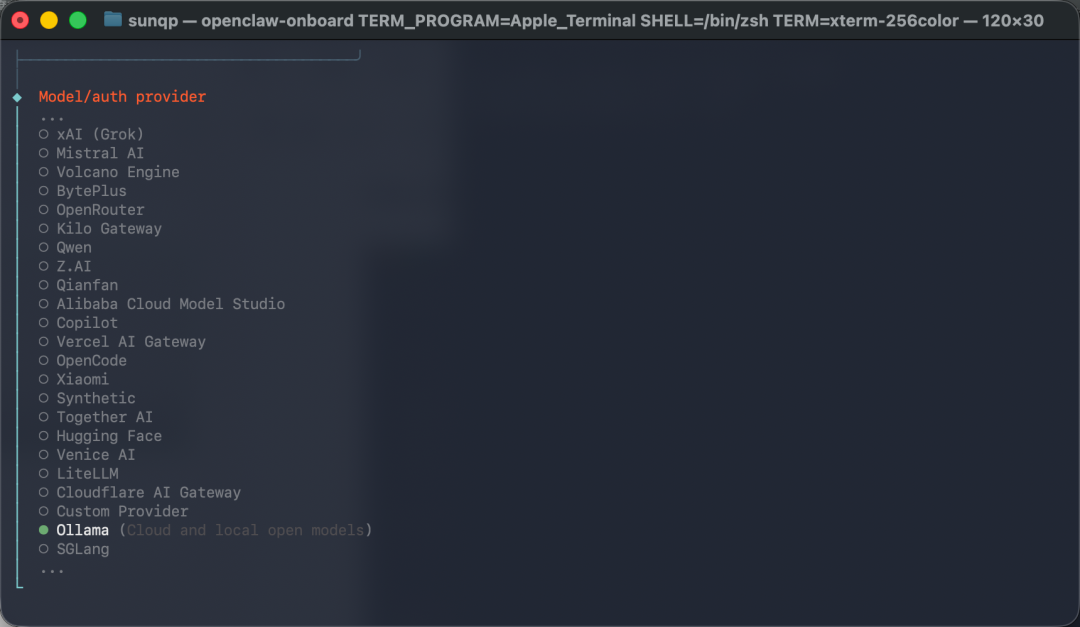
执行测试:
python3 test_ollama.py若实时打印出诗句,说明本地服务正常。
跨设备测试
在同一局域网的手机/另一台电脑运行该脚本(替换 Mac IP),能正常返回结果,即局域网服务配置成功。
🔗 第五步:对接 OpenClaw,实现无 token 无限调用
安装 OpenClaw
curl -fsSL https://openclaw.ai/install.sh | bash配置 OpenClaw 使用 Ollama
- 运行
openclaw onboard开始配置向导 - 跳过大模型配置(因为我们已经安装了 Ollama)
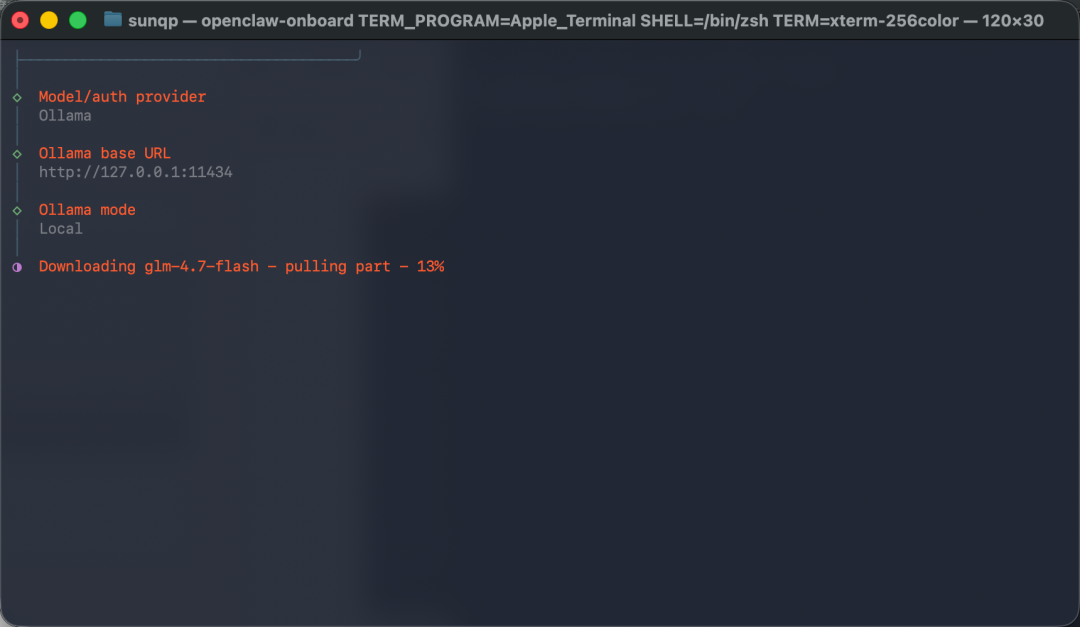
- 在 models 选择中选择 ollama
- 系统会检测已安装的本地模型,选择
qwen3.5:9b - 后续配置项可全部跳过
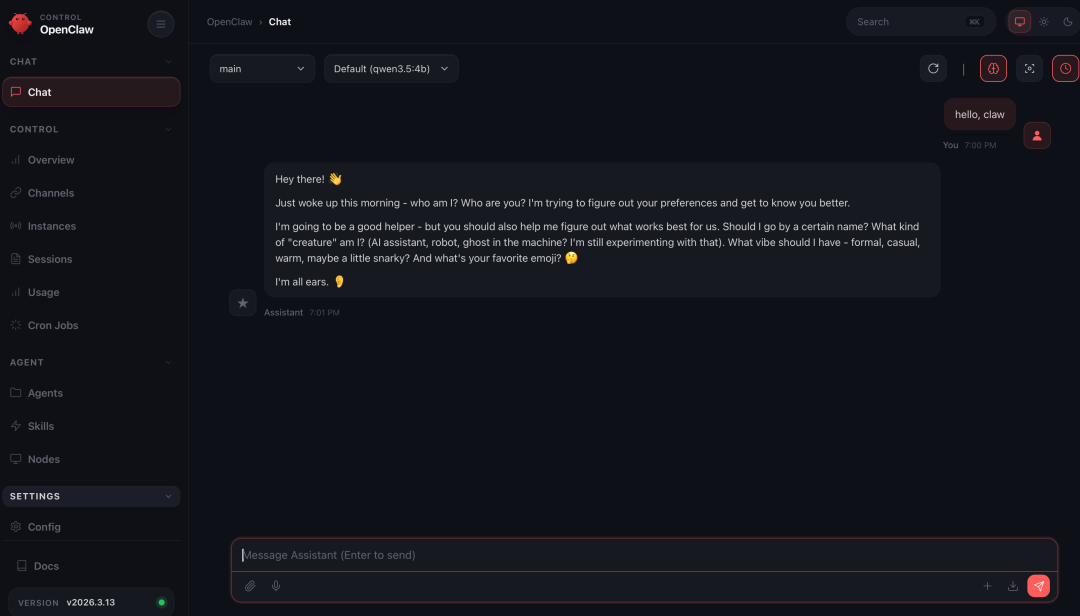
- 最后选择打开 Web UI
出现 Web UI 界面,说明安装成功,现在可以与 OpenClaw 对话了!
💡 Mac 专属通用小贴士
Ollama 后台常驻
- Homebrew 安装版:默认后台运行
- DMG 包版:将 Ollama.app 添加到「系统设置 - 通用 - 登录项」,实现开机自启
模型管理
# 查看已安装模型
ollama list
# 删除无用模型释放空间
ollama rm 模型名本地模型默认存储在 ~/.ollama/models
提升推理速度
- 关闭 Mac「节能模式」(电池设置)
- 别忘了配置前面提到的环境变量
多模型切换
无需卸载原有模型,直接在终端执行 ollama run 新模型名,自动下载并切换,多模型可共存。
📝 总结
Mac 版 Ollama+OpenClaw 部署方案就到这了。现在 Linux、Windows、Mac 版本都有了!
💬 作者体验:个人感觉,在安装过程中,Mac 是安装和适配最好的一个。没想到的是在我的 MacBook Air 上,竟然比 AMD 8845CPU+32G 内存的主力笔记本还快。但是体验一下可以,日常工作感觉还是慢。
有什么问题可以在评论区交流,感谢关注!
📌 更多教程请访问: AiTimes 智能时代