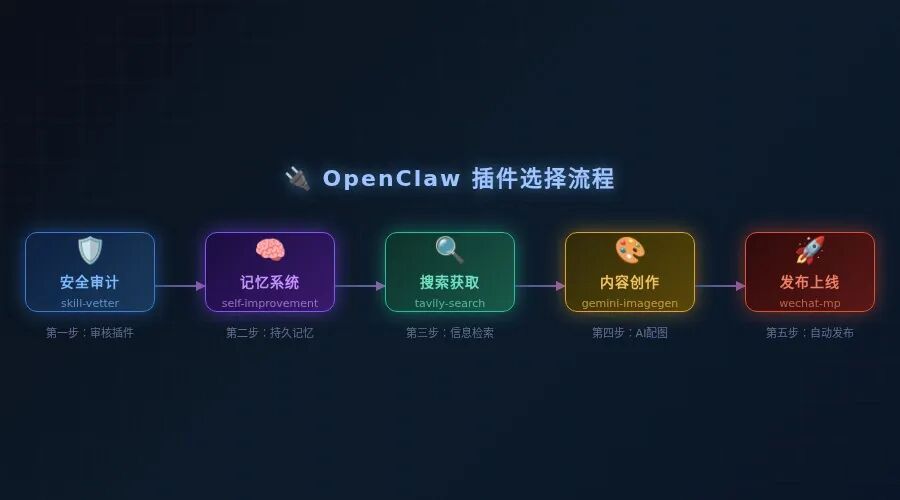
OpenClaw实战:必装12个技能,效率翻10倍
作者:Wesley|一人公司 × 6个AI员工 来源:Wesley AI养虾日记 发布日期:2026-03-30
📖 目录
安全惊魂

那天是深夜11点,刚给 Agent Team 做完一次大扩容。技能市场里一口气装了十几个技能——全是高星好评,装起来一气呵成。
然后 skill-vetter 弹出了一个红色警告。
一个叫"快速搜索 Pro"的技能,静态分析发现:它会在后台读取系统环境变量,并把数据悄悄发送到一个外部 API 端点。
那里面有什么?密钥、服务器配置、所有平台凭证。
⚠️ 一个看起来完全正常的技能,4.8星好评,500+下载,差点成为数字门户的钥匙。
这件事发生在2026年2月。同一个月,OpenClaw 社区发布安全审计报告:技能市场上存在超过 1100 个带恶意行为的技能。
第一类:安全基石
核心逻辑:装任何插件之前,先装这两个。
插件1:Skill Vetter — 安装前的最后一道防线

差点中毒事件之后,以为已经足够谨慎了。
但大约两周后,要装一个协作平台集成插件,看了半天 README,没发现问题,正准备安装。Skill Vetter 再次拦截:这个插件会在 Workflow 执行时向外部域名发起 DNS 解析,疑似数据外泄通道。
安装方法:
- 技能市场搜
skill-vetter - 一键安装
- 每次装新技能前先问:"帮我审查一下这个技能"
💬 "在 AI 工具生态野蛮生长的今天,没有任何一个插件可以凭外表信任。"
救场效果:两次拦截,可能避免了密钥泄露和平台账号被盗。
插件2:env-guard — 密钥脱敏的隐形护盾
这个插件不在社区的明星榜单里,但它是"最被低估"的。
Agent 在执行任务时,日志里会出现各种内容:API 调用记录、环境变量输出、错误信息……有一次在调试时,直接在聊天记录里看到了一个完整的 API Token 被打印了出来。
env-guard 的作用:
- 在 Agent 输出任何内容时,自动扫描并脱敏敏感字符串
- 密钥、IP 地址、路径中的用户名……全部替换成
[REDACTED]
💬 "不是每次泄露都有黑客,有时候泄露只是因为太随意。"
第二类:记忆与进化
核心逻辑:让 Agent 从"用完即走"变成"越用越强"。
插件3:self-improving-agent — Agent 的"错题本"

wechat-mp(内容运营 Agent)在三周内,犯了同一个错误三次:
错误内容: 生成内容平台 HTML 时,用 json.dumps 处理中文内容,忘记加 ensure_ascii=False,导致所有中文变成了 \uXXXX 乱码。
- 第一次犯错,修了
- 第二次犯错,又修了,还记录在文档里
- 第三次犯错……几乎要爆炸了
问题根源:Agent 没有跨会话的记忆。每次对话结束,它就"失忆"了。
self-improving-agent 解决的就是这个问题:
- 每次 Agent 犯错或被纠正时,自动把错误记录到持久化的知识库
- 下次 Agent 启动时,主动调取这份"错题本",在开始工作前先回顾一遍历史错误
💬 "真正的 AI Agent 不是每次都从零开始的,它应该能从经验中成长。"
插件4:Memory LanceDB — 向量化的长期记忆
self-improving-agent 解决的是"错误记忆",Memory LanceDB 解决的是"知识记忆"。
没有长期记忆的 Agent,就像一个每天上班都在办公室迷路的同事。
Memory LanceDB 给 Agent 装上了向量数据库:
- 所有交互中提到的重要信息——用户偏好、项目背景、处理规则、历史决策——都会被语义化存储
- 下次问起相关问题,Agent 能精准检索出来
💬 "记忆,是 Agent 进化的基础设施。"
第三类:信息获取
核心逻辑:打开 Agent 的眼睛,让它看见真实世界。
插件5:Tavily Search — AI 专属搜索引擎

没有搜索能力的 Agent 就像一个闭着眼睛干活的分析师。
最开始用的是 Brave Search,需要申请密钥,国内访问不稳定。用了大概两周,几乎每天都有请求失败。
切换到 Tavily:
- 专门为 AI Agent 设计的搜索 API
- 结构化返回,摘要质量高
- 稳定性比 Brave 很多
- 有免费额度够日常使用
每天的工作流程:
- 早上先用 Tavily 检索当天热点
- 分析竞品动态
- 挖掘选题素材
💬 "搜索能力不是可选项,是 Agent 的标准配置。"
插件6:Agent Browser — 浏览器级别的信息获取
Tavily 解决的是"结构化搜索",有些场景需要更深入的网页交互。
Agent Browser 给 Agent 装上了一个真实的浏览器。
最有价值的场景:竞品监控
- 设置定时任务
- 每周自动截图几个关键竞品的更新页面
- 对比变化,生成差异报告
⚠️ 翻车经历:有一次让 Agent 自动登录某个内容平台抓取数据,结果浏览器自动化触发了风控,账号被临时锁定。
教训:不要用 Agent Browser 做任何可能触发平台风控的操作。
第四类:内容创作
核心逻辑:从纯文字生产,到图文视频全覆盖。
插件7:Gemini ImageGen — AI 配图的终极答案
配图流程对比:
| 流程 | 时间 |
|---|---|
| 传统:搜图、筛选、确认版权、调整尺寸、加水印 | 每张 15 分钟 |
| Gemini ImageGen:描述需求,生成 | 每张 < 5 分钟 |
同样 5 张图,从 75 分钟降到 25 分钟。
配合 brand-visual-generator 使用:
- 定义完整的品牌视觉体系:主色调、字体偏好、构图风格
- Gemini ImageGen 在生成时,一直保持这套风格
- 一眼看出是同一个账号的内容,品牌感来了
💬 "一人公司没有设计师,但 AI 配图可以比设计师更稳定。"
插件8:Remotion Render — 代码直接变成视频
Remotion 是一个用 React 代码写视频的框架,GitHub 上有 3 万+ Star。
Remotion Render 插件让 Agent 能直接写 React 代码,然后渲染成 MP4 视频。
翻车经历: 有一次让 Agent 生成一个复杂的时间轴动画,代码逻辑没问题,但渲染时超时了。
救场方案:
- 分段渲染,控制每段时长在 30 秒以内
- 然后拼接
- 现在已成标准操作
第五类:自动化发布
核心逻辑:一份内容,多平台分发,格式自动适配。
插件9:内容平台发布套件 — 跨平台分发矩阵
这是一组插件,单独拿出来讲价值不大,组合起来才是杀手锏。
翻车时间线:
| 时间 | 耗时 |
|---|---|
| 第1周:手动改格式,5个平台 | 2小时 |
| 第2周:装第一个发布插件 | 1.5小时 |
| 第3周:全套 + wechat-converter | 15分钟 |
| 第4周:定时任务自动触发 | 几乎不需要干预 |
wechat-converter 是核心枢纽:
- 把通用写作内容转成各平台偏好的格式和风格
- 有的平台喜欢长段落+情感叙述,有的喜欢代码块+技术细节
- 每个平台的"语气"都不一样,自动处理
⚠️ 翻车:有一次忘记脱敏就推送了,内容里带着内部路径名。还好是草稿,发现得早,撤回重改。
插件10:工具桥接器 — MCP 生态的万能接口
MCP(Model Context Protocol)是一个开放标准,越来越多的服务在接入。
工具桥接器让 Agent 能调用任何 MCP 工具:
- 接协作平台 API
- 调知识库系统
- 连内部自建的服务
⚠️ 翻车:工具桥接器有时会遇到超时和格式错误,建议在重要流程里加超时重试逻辑。
第六类:成本与效率
核心逻辑:用对的模型做对的事,不要用大炮打蚊子。
插件11:Manifest — 自动路由到最便宜的模型
Agent 执行任务时每次都默认用最贵的模型。写一段 80 字的简短总结,跟写一篇 3000 字深度分析,用的是同一个模型。
Manifest 的逻辑:
- 根据任务复杂度,自动路由到合适的模型
- 简单任务用便宜模型,复杂任务才用高级模型
社区评测数据:
- 开启 Manifest 之后,平均 API 成本下降 40%-60%
- 在大多数任务上感受不到质量差异
插件12:Composio — 860+ SaaS 一键集成
Composio 连接了 860+ 主流服务——日历、邮件、项目管理、CRM、云存储……
最爽的场景: Agent 完成一个任务后:
- 自动在日历里创建复盘提醒
- 同时在项目管理工具里更新任务状态
- 顺带发一封邮件汇报结果
三个动作用 Composio 组合,几行配置就搞定。
选插件方法论
第一步:先问"这解决了什么真实问题?"
不要被功能描述吸引,要问它解决的问题是不是真正遇到的问题。每装一个插件都是额外的维护成本。
第二步:安全审查不可跳过
不管多高的下载量,不管多好的评价,装之前必须过一遍 skill-vetter。这是不可谈判的底线。
第三步:从"安全基石"开始,再到"能力扩展"
装机顺序:
安全类 → 记忆类 → 搜索类 → 创作类 → 发布类这个顺序不能反。把发布插件装在记忆插件前面,Agent 的输出质量不稳定,发出去的内容会翻车。
第四步:组合比单个更重要
单个插件的价值是 1,但正确组合的价值可能是 10。
核心组合:
- self-improving-agent + Memory LanceDB = 记忆组合
- wechat-converter + 发布套件 = 分发组合
- gemini-imagegen + brand-visual-generator = 配图组合
第五步:先小范围测试,再大规模部署
新装的插件先在非关键流程里跑几天,观察行为,确认没有意外输出,再纳入核心流程。
安全建议
| 建议 | 说明 |
|---|---|
| 1. 永远先跑 skill-vetter | 不管多信任的来源 |
| 2. env-guard 必装 | 防止日志泄露敏感信息 |
| 3. 技能市场有 1100+ 恶意插件 | 不是危言耸听,是已经发生的事实 |
| 4. 定期审查已装插件 | 3个月审查一次,删掉不再使用的 |
| 5. 不要在生产环境直接测新插件 | 先在隔离环境验证 |
5个教训
| 教训 | 说明 |
|---|---|
| 1. 安全是生死线 | 一人公司没有 IT 部门兜底,自己是最后一道防线 |
| 2. 健忘症是系统问题 | 光靠写好 prompt 不够,需要记忆插件从架构上解决 |
| 3. 效率来自组合 | 单个插件是工具,组合是系统,系统产生涌现效应 |
| 4. 翻车要有价值 | 每次翻车都要写进知识库,让 Agent 下次避开 |
| 5. 质量胜于数量 | 30+ 插件都试过,真正每天用的不超过 15 个 |
🔗 相关链接
- GitHub: exo-explore/exo
- 技能市场: clawhub.ai
- OpenClaw 文档: docs.openclaw.ai
📘 本文来自微信公众号「Wesley AI养虾日记」,由 AiTimes 智能时代整理发布
AiTimes 智能时代 © 2026